【第98回】ロータス博士のWinActor塾~正規表現Ⅲ


さあ、今日は前回出した問題の解答編じゃ!

待ちわびましたよ。
僕のシナリオが正解かどうか、ついにわかるってことですね。
最近はワシも忙しくてな。すまぬ。
もう待ちきれません!
茶番はいいので早く解答を!

茶番・・・。
課題のおさらい
前回は、入力された文字が「0~5」の範囲内であるかを判定するために正規表現を使用し、[0-5]と指定しました。
この指定をすれば確かに0~5はマッチします。
しかしこの正規表現では、他の文字が混ざっていた場合に正しい結果が得られません。
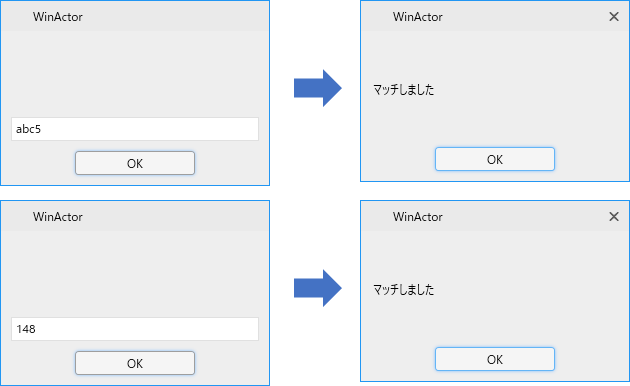
このように1文字でも0~5が含まれているとマッチしてしまいます。
これを0,1,2,3,4,5の5パターンのみマッチするように変更したいというのが前回の課題です。
前回の記事はこちら

問題点を探る
ではどこが問題なのかを考えていきましょう。
[0-5]では、確かに0~5が存在しているかどうかを調べることができます。
しかし、それらがいくつ存在しているかまではわかりません。
1つでも、2つでも、存在していれば個数を問わずtrueになります。
ここでロータス君の解答を見てみましょう。

僕の解答を!?
あれ動かしてみたら失敗したと思ったけど、もしかして?
ロータス君の解答

[0-5]{1}
ロータス君が先に自白したように、結果は失敗になります。
じゃあなんで見せたん・・・?
良い失敗例としてロータス君の作成した正規表現をお見せしました。
この正規表現でやろうとしているのは「文字数」の指定です。
量指定子を使用して{1}と書くことで、直前の文字が1個連続した場合にマッチするようにしています。
これがなぜダメなのか、ロータス君は{1}を指定しましたが、{3}の場合の例でお見せします。
[0-5]{3}
この正規表現に対して「11」を入力してみましょう。
これはマッチしません。量指定子で{3}と指定すると「直前の文字が3個連続した場合」という意味になります。
3文字と指定しているのに入力が2文字なので当然ですね。
「111」では文字数が一致しているのでマッチします。
もちろん1は0~5の間の数字なので[0-5]の条件も満たしています。
ここまでは良さそうです。問題は文字数が指定より大きい場合です。
「1111」は4文字なので、マッチしてほしくありません。しかし、実際はマッチしてしまうのです。
なぜかというと、「1111」の中に「111」が含まれているからです。
この正規表現の条件を日本語にすると「0~5の文字が3つ連続した部分が含まれていれば一致」となります。
「1111」,「1111」
赤色の部分を見ると、4文字でも条件に一致していることがよくわかりますね。
解答例
ここまでの例で、なぜこのような問題が発生するかというと
正規表現を満たす文字列が「含まれている」場合にマッチしてしまうからですね。
これを「完全に一致」した場合にのみマッチとなれば解決しそうです。
なぜなら「指定以外の文字はどこにも入ってほしくない」からです。
こういった場合には、文字列の位置を指定するための正規表現「ゼロ幅アサーション」が役に立ちます。
| 要素 | マッチ箇所 | 例 |
| ^ | 文字列の先頭 | ^abc = abcで始まる箇所にマッチ |
| $ | 文字列の末尾 | abc$ = abcで終わる文字列にマッチ |
この2つの要素を同時に使用することで、完全一致にすることができます。
例えば^abc$とすると「始まりから終わりまでがabcである文字列」にマッチします。
ここで気を付けたいのは「abcで始まりabcで終わる」ではないことです。
「abcで始まってabcで終わっていれば間に何か入っていてもOK!」では困りますよね。
余談ですが、逆にそういった指定であれば^abc.*abc$といった形であったり、
abc単体もマッチしたい場合は(?=^abc.*)(?=.*abc$)と書いたりします。
今回の問題を解決するには完全一致にできれば良いので、^と$を付ければうまく動くでしょう。
ゼロ幅アサーションを使って「始まりから終わりまでが0~5である文字列」という正規表現を作成します。
シナリオの修正
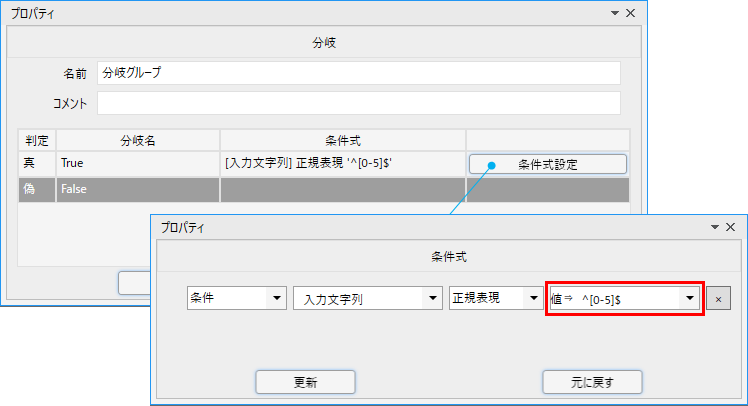
^[0-5]$
これを以前作成したシナリオの分岐ノードの条件に指定してみましょう。
分岐グループのプロパティを以下のように変更します。
実行結果
それでは実行してみましょう。
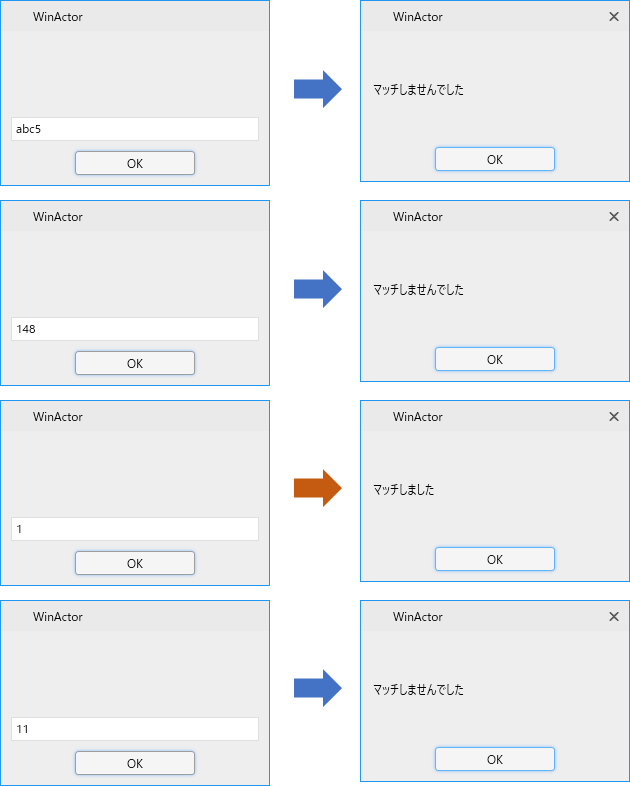
上図の通りの結果となりました。
これで「11」や「148」などがマッチしてしまう問題が解決できましたね!
^と$を最初と最後に付ければ
文字列全体に対してのマッチになるというわけじゃな。
なるほどなあ。
文字数ばかりにとらわれてしまった。
余談のところにも出てきたが、まだ紹介していない表現もある。
難易度が高いが使えれば幅がぐっと広がるじゃろう。
あのわけわかんないやつですか?
あれやるんですか!?
まあ、いずれじゃな。少しずつやっていこう。
いつも言ってる通り、暗記する必要はないからのう。
ではまた次回、お会いしよう。
なんか今日は全体的に落ち着いた雰囲気で終わったなあ。
これがチルいってやつか・・・。
関連記事こちらの記事も合わせてどうぞ。

2026.04.10
【第111回】ロータス博士のWinActor塾~画像マッチング自動記録

2026.01.28
【第110回】ロータス博士のWinActor塾~シナリオ差分表示
")
2025.12.05