【第96回】ロータス博士のWinActor塾~正規表現Ⅰ


今日はなんと正規表現じゃ。
ここまでくるともう上級者じゃぞ。

久し振りの塾!そしてなんだか難しそう!
全てを理解しようとするとなかなか難しいぞ。
じゃが、その必要はないのじゃ。
・・・と言いますと?
正規表現には定型的に使われるパターンがあってのう。
それの一部を書き換えれば誰でも使えるのじゃ。
今回はそれを紹介するから実際に使ってみよう!
正規表現とは
そもそも正規表現とは何でしょうか。
Wikipediaで調べると「文字列の集合を一つの文字列で表現する方法の一つ」と書かれています。
簡単に言うと、ある文字列の規則を記号などを使って示したものです。
正規表現にはいくつかの記法があり、システムが採用している正規表現によって記述が異なります。
WinActorで使用される正規表現は.NETのSystem.Text.RegularExpressions.Regexクラスに準じます。
詳細なフォーマットはこちらのリンクから確認できます。

もう既に難しくて頭に入ってこないんですけど・・・
なに、心配するでない。わからなくても大丈夫じゃ。
というかこれに関しては実際に使ったほうが理解が早いじゃろう。
そもそも正規表現ってどんなときに使うんですか?
文字列のフォーマットが合っているかどうかを判定するのに使われるのじゃが
その判定に幅を持たせることができるのじゃ。
「Aから始まる」や「間にスペースが2つ以上ある」といった細かい条件を付けて
それに一致しているかどうかをチェックすることができるのじゃ。
え、それって使えるようになったら物凄く便利では・・・
かなり便利じゃ。しかし最初に言った通り難易度も高めじゃからな。
ゆっくりと習得していこう。
正規表現はどこで使われる?
正規表現は、主に文字列に対して判定を行うタイミングで使われます。
WinActorでは分岐ノードの条件式やウィンドウ識別ルール、マッチングを行うタイプのノード等で使うことができます。
分岐ノードで正規表現を使う
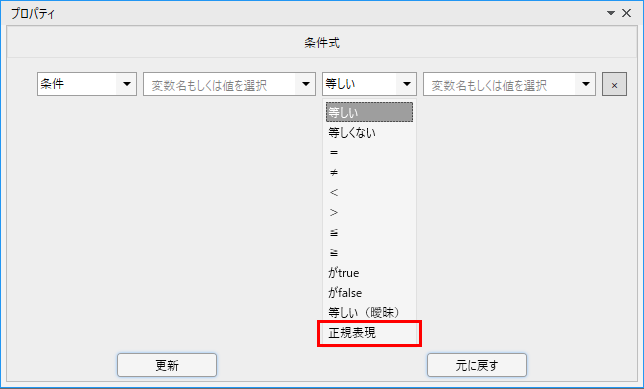
分岐ノードを配置した後にプロパティを開き、条件式の設定ウィンドウから
条件式の比較演算子(=や<など)として選択することができます。
左辺にチェック対象にしたい文字列、右辺に正規表現のパターンを記述して使用します。
ウィンドウ識別名に正規表現を使う
ウィンドウ識別名にも正規表現を指定することができます。
まずは判定対象としたいウィンドウをキャプチャしてウィンドウ識別ルールを作成します。
![]()
画面上部にあるツールアイコンから、ウィンドウ識別ルールの一覧を開き
取得済みのウィンドウ識別ルールを選択します。
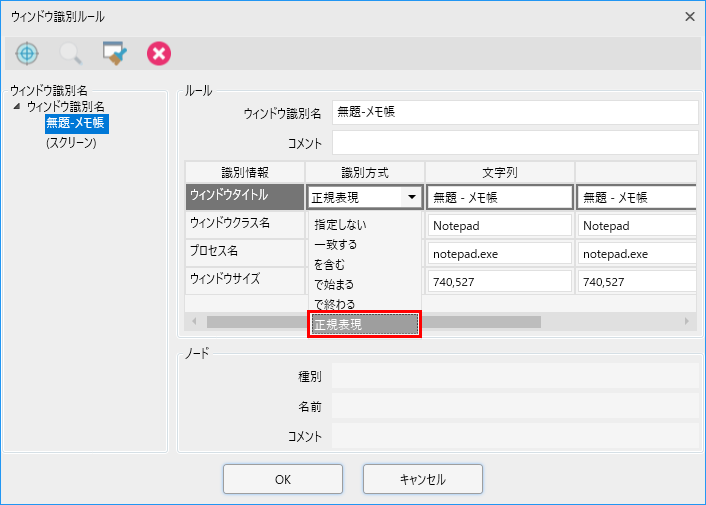
選択すると、右側のルール編集エリアに情報が表示されます。
この中の「ウィンドウタイトル」の識別方式に正規表現を使用することができます。
ここで正規表現を選択した場合、「文字列」列に正規表現のパターンを記述して使用します。
正規表現が使えるノード・ライブラリ
他にも、特定のノードやライブラリでは正規表現を使用できるものがあります。
![]()
これは名前の通りですが「正規表現(文字列置換)」ライブラリのプロパティを見てみると
正規表現を入力する欄があります。
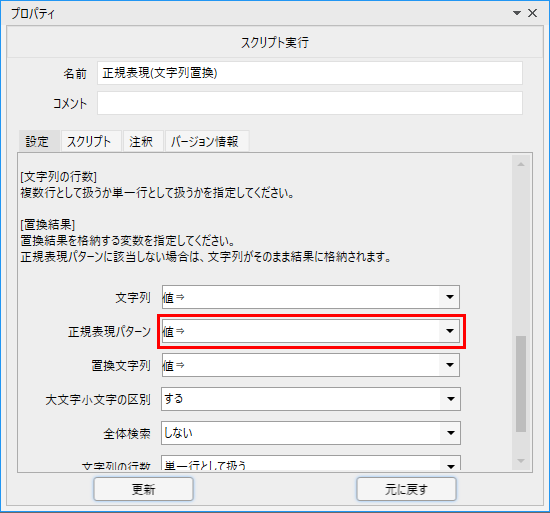
こうしてみると設定できるところって意外と多いですね。
そうじゃな。基本的にWinActorでは正規表現を使わなくても良いようになっておる。
正規表現を使わなくても、ライブラリが豊富に用意されておるから困ることはない。
しかし、使おうと思えば使えるようにもなっておるのじゃ。
確かに、これまで正規表現なんて使ってきませんでしたけど
それでも普通にシナリオは作れてましたね。
だから上級者向けってことなのか・・・!
正規表現の例
正規表現の入門として、3つの例を用意しました。
これが正規表現パターンの記述です。
| 正規表現パターン | 説明 |
| ^(ABC).*$ |
「ABC」から始まる文字列かどうかを判別します。 |
| .*(ABC)$ | 「ABC」で終わる文字列かどうかを判別します。 |
| ^R.*S$ | 「R」から始まり「S」で終わる文字列かどうかを判別します。 |
ウィンドウ識別名の条件として「~から始まる」や「~で終わる」は標準で選択できます。
せっかくなので、ここでは選択肢にない「~から始まり~で終わる」という上の2つの条件を合わせた正規表現を用意しました。これを使って文字の判定を行ってみましょう。
テスト用シナリオ
正規表現の例を確認するために、次のようなテスト用シナリオを準備しました。
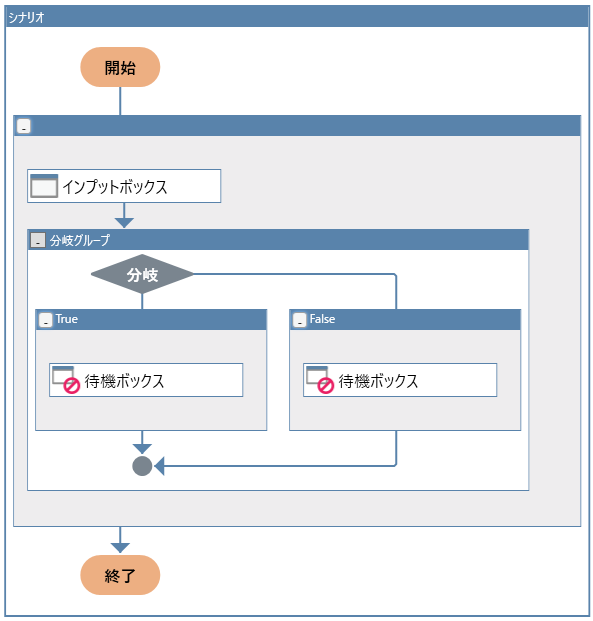
仕組みは単純で、最初のインプットボックスで変数「入力文字列」にユーザが入力した文字列を格納します。
その後分岐ノードに入り、条件がTrueであればフロー左側の待機ボックスへ、Falseであれば右側の待機ボックスへ遷移します。
左側(True)では「OK」と表示され、右側(False)では「NG」と表示されるように設定しています。
分岐ノードに指定している条件は次のようになっています。
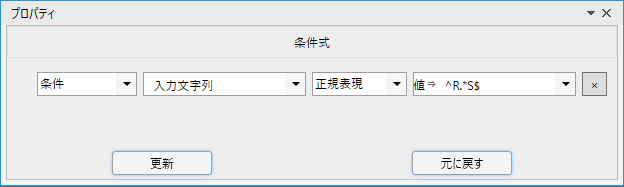
入力文字列の文字の並びが、正規表現の「^R.*S$」に一致した場合にTrueが返ります。
この場合「Rで始まりSで終わる」文字列の場合にTrueとなります。
Rで始まってSで終わるといえば・・・

RoTAS!!
ということで、いろいろと入力して試してみましょう。
実行結果
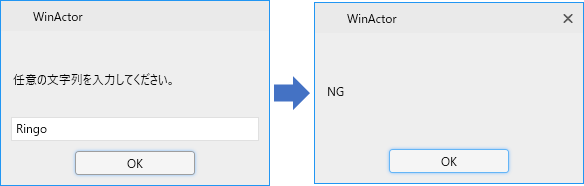

これはまあ、Sで終わってませんからね。
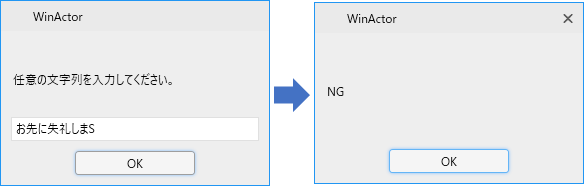
これは無理があるでしょ!
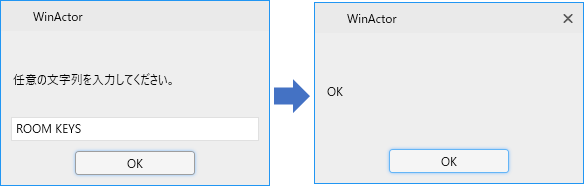
あ、OKだ。ここはRoTASじゃないんだ・・・。
まあRで始まってSで終わってますね。
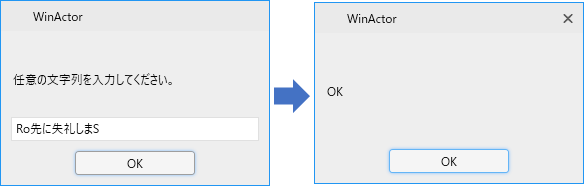
ろ先に失礼しまス!?
このように、正規表現が正しく機能していることがわかりました。
ここまでである程度、正規表現とはどのようなものかが理解できたかと思います。
正規表現の書き換えについて
今回例として紹介した正規表現は以下の赤文字の部分を書き換えることで
目的に合った条件としてご利用いただけます。
^(ABC).*$
.*(ABC)$
^R.*S$
例えば「DEFから始まる」文字列のパターンをチェックしたい場合は
^(ABC).*$
を
^(DEF).*$
というように変更します。
どうじゃ?なかなか面白いじゃろ。
次回以降はさらに詳しく掘り下げていくぞ。
ちょっと博士!最後の実行結果はなんですか!
RoTASはどこにいったんですか!
正規表現は確かに面白いですけど・・・!
まあまあ、ちょっとした遊び心じゃよ。
なんか上のほうで僕めっちゃ元気に
RoTAS!!
とか言ってたのが馬鹿みたいじゃないですか。

それはスマン。
とにかく、今回で正規表現がどんなものか掴んでもらえたじゃろう。
この調子で次回も頑張っていこう!
そこはかとなく誤魔化してるニオイを感じますけど、まあいいでしょう。
それじゃ、Ro先に失礼しまS。
気に入っとるんかい!
関連記事こちらの記事も合わせてどうぞ。

2026.04.10
【第111回】ロータス博士のWinActor塾~画像マッチング自動記録

2026.01.28
【第110回】ロータス博士のWinActor塾~シナリオ差分表示
")
2025.12.05