【第45回】ロータス博士のWinActor塾~文字列操作Ⅱ


今回は文字列操作の中の「比較」について学んでいくぞ。
操作と言いつつ、文字列そのものを変化させることはない。
2つの文字列の関係がどうなっているかを調べるのが目的じゃ。

2つの文字列を比べて、その結果に応じて処理内容を変えるってわけですね!
そうなると分岐ノードと組み合わせて使う感じでしょうか。
今日は冴えとるのう!
文字列比較のライブラリは実行すると変数に結果が格納される。
その結果によって処理を決めるわけじゃ。つまり分岐ノードは必須ということじゃな。
ではひとつひとつ見ていこう。
前方一致比較
前方一致について
前方一致比較ノードは、名前の通り文字列の前方(頭の部分)をチェックします。
例えば次のような文字列を用意します。
自動で動くロボット
この文字列に対して「自動」で比較を行ってみましょう。
今回は前方比較一致ですので、文字列の先頭から一致するかどうかが調べられます。
自動で動くロボット
自動
先頭の2文字がどちらも「自動」でしたので、比較結果は正となります。
では次の文字列ではどうでしょう。
ロボットによる自動化
この場合、自動という文字は確かに含まれていますが、前方一致比較としてはNGとなります。
NGになる理由は単純で、「自動」が文字列の先頭に無いからです。
ロボットによる自動化
自動
この例では最初のロの時点でNGですね。
このように、文字列の先頭から比較されていき
異なる文字であった場合即座にNGが返されるのが前方一致比較です。
使い方
まずはノードを配置してみましょう。
ライブラリは下記の階層にあります。
NTTATライブラリ > 06_文字列比較 > 前方一致比較
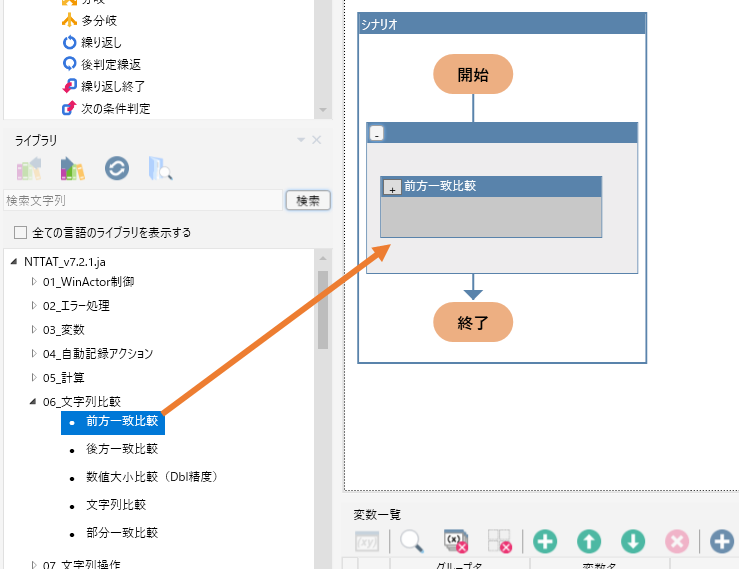
ライブラリをフローチャートエリアにドラッグ&ドロップすると
グループが閉じた状態のものが配置されます。
このグループは左上の「+」の部分をクリックすることで展開されます。
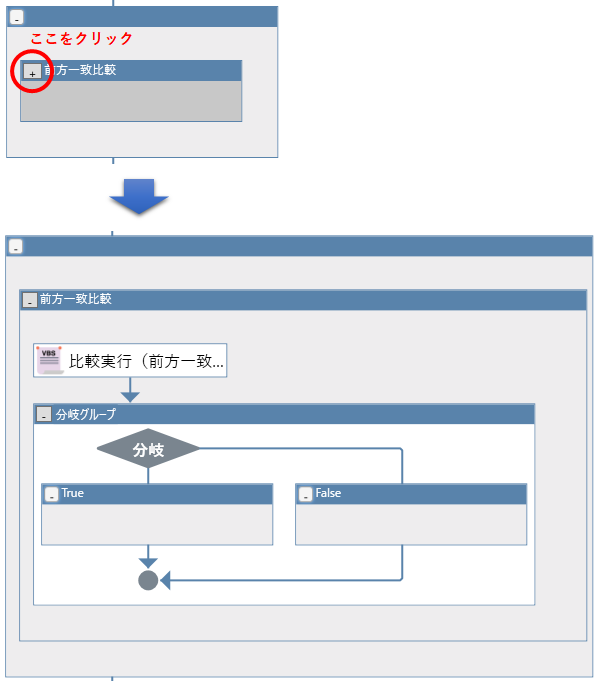
分岐グループとセットになっていることがわかります。
※分岐グループも最小化されているので同様の手順で展開してください。

ライブラリってフローが付いてるものもあるんですね!
うむ、なかなか便利じゃろう。
ほとんどはその機能を持ったノード単体でライブラリとなっているが
比較は分岐まで含めてライブラリ化されておるのじゃ。
試しに分岐ノードの設定を見てみよう。
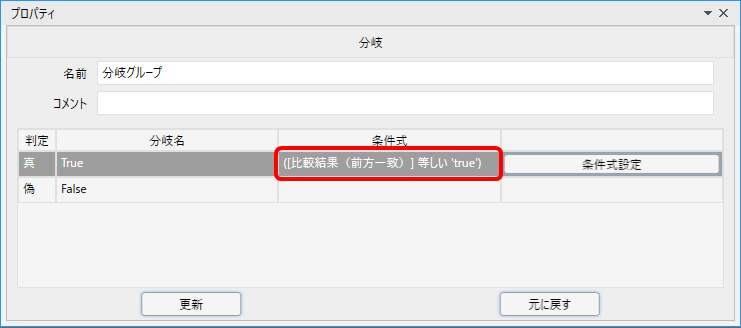
もう条件が入ってる!
なんて親切なんだ・・・。
そう!このようなライブラリを使えば、わざわざ自分で分岐処理を作る必要がないのじゃ。
前方一致比較では、一致したらTrueに、NGだった場合はFalseに処理が流れるぞ。
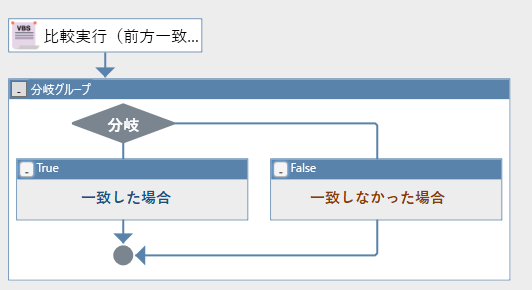
続いて、プロパティも確認しましょう。
このライブラリには比較対象となる文字列と、比較するキーワードの2つを設定します。
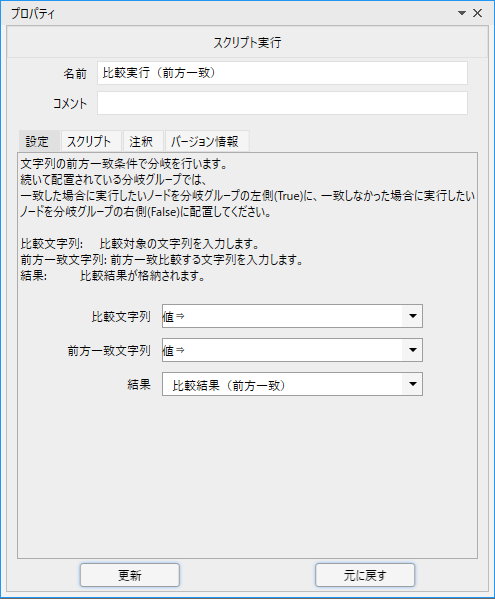
既に変数が指定されている「結果」は特に変更する必要はありません。
ライブラリを配置した時点で、自動的に変数が作成されています。
実行時にはこの変数に結果が格納され分岐に利用されます。
初の文字列操作じゃからな、練習問題をしてみよう。
次のようにプロパティを設定した場合、フローはどのように流れるかの?
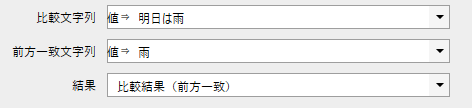
雨というキーワードは比較文字列にあるけど、これは前方一致だから・・・
手前からチェックすると「明」≠「雨」でNGになりますね。
ということはFalseに流れる、ですか!?
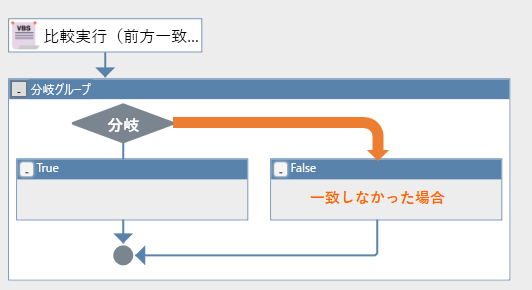
うむ!大正解じゃ!
この流れがわかれば比較はほぼできたようなもんじゃぞ。
他のライブラリも同じような形で、チェックのルールだけが変わる感じじゃからな。
後方一致比較
後方一致について
後方一致比較ノードは、前方一致の逆で文字列の後方(末尾の部分)をチェックします。
先ほど例にも出たこちらの文字列で確認してみましょう。
明日は雨
では「雨」というキーワードで比較を行います。
前方一致ではNGだとロータス君が示してくれましたが、どうでしょうか。
明日は雨
雨
皆さんお分かりのように今回の比較結果は正となります。
後ろから見たときに文字列が一致しているためです。
もちろん次のような場合だと比較は失敗します。
明日は雨です
雨
また、後方の何文字かが同じになっていても、キーワードの文字列全てが一致しなければNGです。
これは前方一致比較でも同様です。
明日は雨です
雷雨です
使い方
使い方は前方一致比較と全く同じで、比較のルールが後ろからチェックされるように変わっただけです。
ライブラリを配置すると次のようになります。
NTTATライブラリ > 06_文字列比較 > 後方一致比較
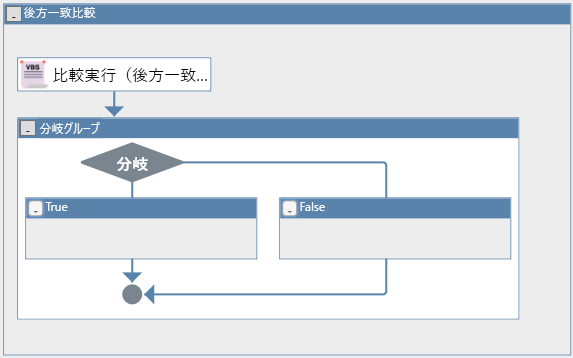
配置と同時に「比較結果(後方一致)」という変数が追加され、分岐に使用されます。
分岐ノードの条件式も設定されており、比較に成功した場合はTrue、失敗した場合はFalseに処理が流れるところも同様です。
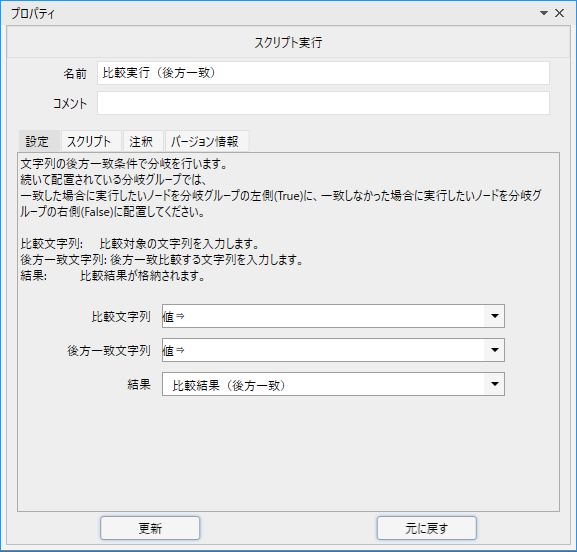
プロパティの設定方法も同じです。
「比較文字列」に対して「後方一致文字列」に指定したキーワードでチェックを行います。
比較の利用
使い方はわかったんですけど、これって実際
シナリオのどこで使うんですか?
全然イメージがわかなくて・・・
よい疑問じゃな。こういうタイプのライブラリは、内容を理解しても
使いどころがわからないという人が多いんじゃ。
早速、前方一致と後方一致の使いどころについて紹介するから是非覚えてほしい。
前方一致の利用
文字列の先頭や末尾が特定のキーワードと一致していることを調べるこれらのライブラリは
主にファイルを扱う際に活躍します。
例えば、次のようなファイルが入ったフォルダがあるとします。

この複数の予定表のうち、2021年のものだけを使いたいといった場合は前方一致が利用できます。
フォルダ内のファイルは「4桁の西暦で始まる」という規則性があるため
ループでファイル名を取得していく際に「2021」というキーワードで前方一致比較をすることで
2021年以外のファイルを除外することができます。
このようにファイル名の先頭に規則性がある場合に前方一致比較は有効です。
後方一致比較の利用
こちらもファイル名に対して威力を発揮します。
先ほどのフォルダにテキストファイルを入れてみましょう。
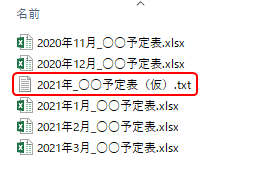
テキストファイルは開く必要がないといったシナリオを考えてみましょう。
このフォルダ内のファイルをループで順次処理していくと、テキストファイルも開かれてしまいます。
こういった場合は、後方一致比較を次のように利用することで、ファイルの種類を選別することができます。
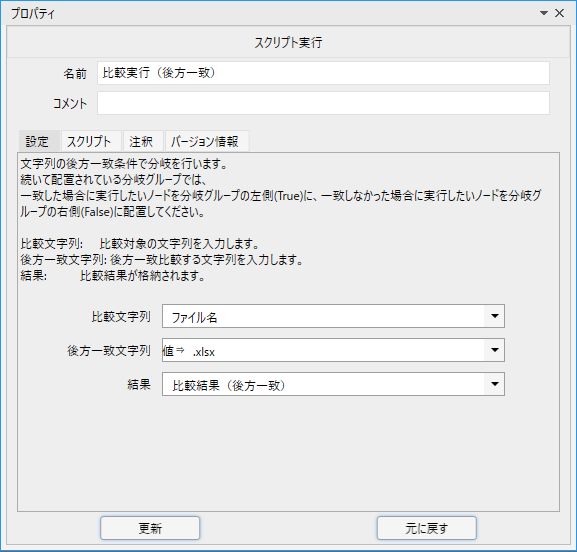
取得したファイル名を「ファイル名」という変数に格納しておき、キーワードを拡張子にします。
今回はエクセルファイルを開きたいので、キーワードは「.xlsx」となります。
このように設定することで、そのファイルの名前の末尾(拡張子)でエクセルかどうかを判定できます。
Trueのときにだけファイルを開くようにすれば、エクセル以外のファイルを開くことがなくなります。
なるほど!拡張子をキーワードにすれば
任意の種類のファイルだけ見つけられますね!
文字列操作関連は奥が深い。
外部から取得してきた文字列をこうして比較チェックすることによって
間違った動作を防ぐという役割もこなすことができるのじゃ!
キーワードも変数にできるから、タイミングによってチェックするワードを変えたり
色々と応用が利きそうですね。
今日は本当に冴えておるのう。
変数にすることで扱える幅が広がるのももちろんじゃが、
文字列操作のライブラリは文字列操作と組み合わせることでさらに強力なものになるのじゃ!
次回はまた違ったライブラリを解説しよう。お楽しみに!

関連記事こちらの記事も合わせてどうぞ。

2026.04.10
【第111回】ロータス博士のWinActor塾~画像マッチング自動記録

2026.01.28
【第110回】ロータス博士のWinActor塾~シナリオ差分表示
")
2025.12.05